Background: Vision-Language Models (VLMs) produces responses that are irrelevant to the visual content and are called hallucinations.
Objective: This study analyses the layer-wise thought processes of VLMs to understand and detect hallucinations.
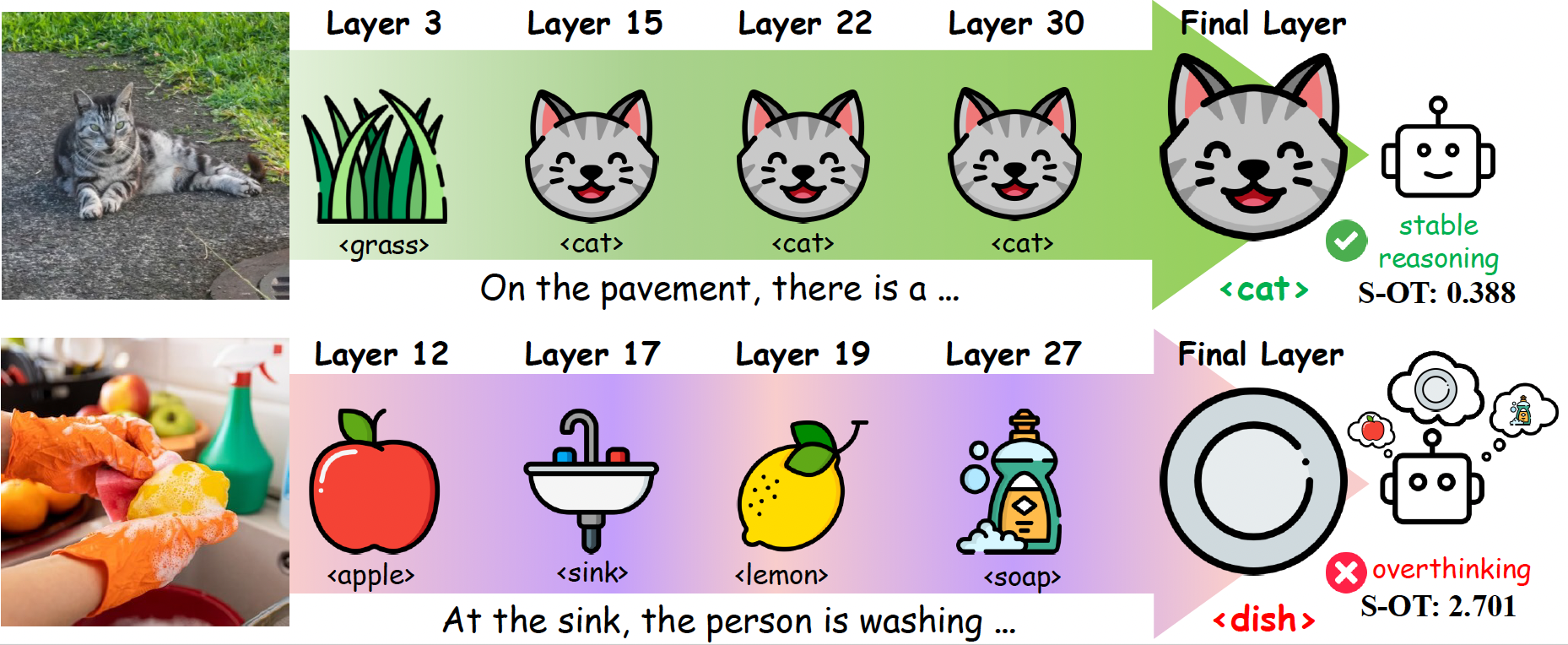
Analysis Results: By observing the layer-wise tokens via Logit-Lens, we find that models repeatedly revise object hypotheses across layers
before committing to an incorrect answer, a behavior we term "overthinking".
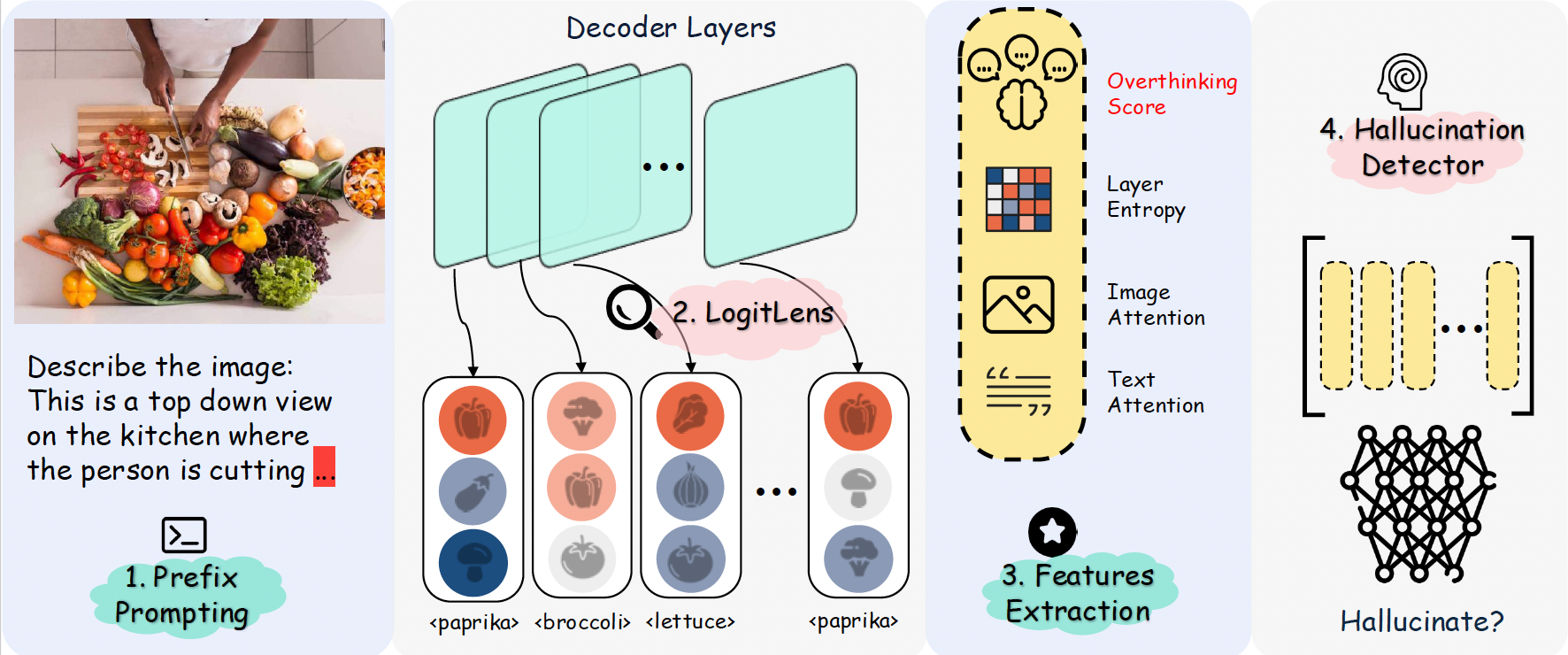
Method: We introduce the Overthinking Score, a metric measuring how many competing hypotheses the model entertains and how unstable these hypotheses are across layers. Light-weight binary classifiers are trained using this score to detect hallucinations.
Results: The Overthinking Score significantly improves hallucination detection: 78.9% F1 on MSCOCO and 71.58% on AMBER.